背景
内存分配是内存管理机制的一部分,本文聚焦一些,只记录内存分配这一小部分内容。简单来说内存分配就是我们管理一大块内存池,每次收到分配内存请求,就从内存池内按请求要求划出一部分交付出去使用,等请求方用完内存后还需要将占用的内存归还给我们以备后续请求继续使用。
最常见的需要考虑内存分配问题的是操作系统。作为内存管理的一部分,操作系统要在每个进程需要分配内存时候从总的内存空间中分配一部分给进程使用。但有时候进程也需要自己处理内存分配问题,例如为了提高性能减少去系统分配内存时产生的系统调用开销、提高内存使用的本地性,先一口气分配一大块内存作为内存池,随后在实际要使用内存时从自己管理的内存池内分配内存来使用。所以了解内存分配机制对应用程序的开发也有好处。
Wiki 上有内存管理相关基础内容可以参考。Memory management - Wikipedia
内存分配机制面临的问题
内存分配机制看似简单,但在实际中可能会遇到很多问题,例如:
- 多 CPU 之间的竞争。现在系统都是多个 CPU 一起运行,在运行时它们都要频繁的分配内存,如果所有 CPU 都在同一块内存池上做分配,势必会引入大量的竞争,为了解决竞争可能引入锁机制,引入锁后性能又会大幅度降低。
- 内存碎片。下面详细说一下。
- 需要减少维护内存分配信息导致的内存占用。分配内存的算法势必需要维护一些背景信息,例如哪块内存分配出去了哪块没分配等,这部分开销要尽可能的少。
- 需要考虑到 Cache Locality。同一个 CPU 连续分配的内存如果能连续那可能可以提高 Cache 的本地性来提升系统性能。分配内存的系统也要尽力照顾到这里,以提升应用运行性能。
- 不好测试。这块挺有意思的,即分配内存的算法怎么做性能评测。只是单纯的测试分配、释放内存速度是不够的,例如有没有照顾到分配出去内存的 Cache Locality 特性也会影响程序运行性能,分配、释放内存快但分配内存的 Cache Locality 差可能程序本身运行的就比较慢。也就是说内存分配机制甚至能完整影响程序整个生命周期的运行效率。测试如果拿一个正经程序来测,可任何程序都有自己的分配、释放内存的模式,可能评测下来在一种模式下性能很好,另一种模式下性能又不行了。所以不太好评测。
内存碎片的话分内部碎片和外部碎片两种。借用这个视频里的图来说这俩概念吧:
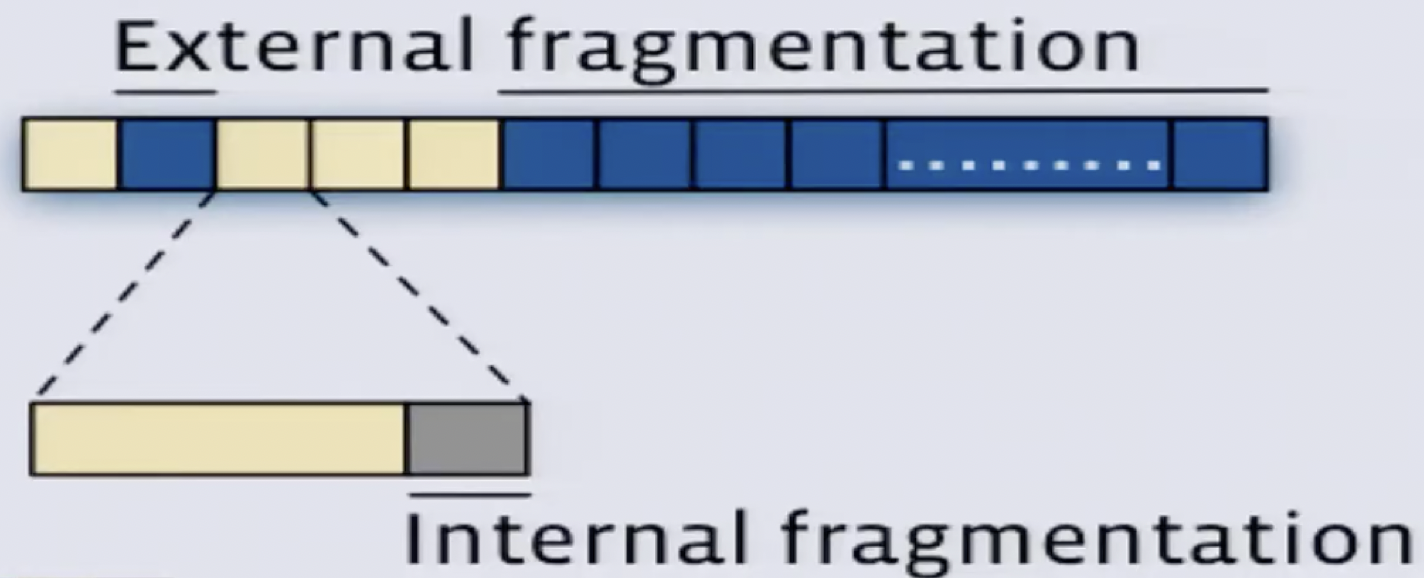
图上每个块就是最小的内存分配单元,蓝色的是未分配的,黄色是已分配的。在图上这种情况下,如果要申请连续的两个内存块,就只能从第 6 个块开始分配,第 2 个蓝色块就是外部碎片,它没有被分配出去又实际占着内存空间,但因为太小了又一直分配不出去,就是外部碎片。内部碎片的话就是放大的黄色内存块,例如一个内存块是 4KB,分配出去后应用程序只有 3KB 数据要存储,留下的 1KB 数据就是内部碎片。
Free List
最简单直接的分配算法。在 Operating System: Three Easy Pieces 的内存管理一节有好多介绍。借用书上的图:

即维护一个大链表将已知的空闲内存块地址用链表连接起来,这个链表称为 Free List。上图中表示 Free List 链接了三块空闲内存,大小分别是 10,30,20。除了会记录大小之外,Free List 上的节点还会记录空闲内存开始位置等信息。内存分配过程也很简单,有 Best Fit、Worst Fit、First Fit、Next Fit 等等策略,不再赘述,随着上面链接去看原文好了。
关键点在于,Free List 上每块内存大小都是不固定的,每次分配的内存会按照申请大小分配,不会有内部碎片,只会有外部碎片。例如 Free List 如上图所示,用 First Fit 策略要分配 5 个内存单位出去,分配完后返回的就是 5 个内存单位的内存块,Free List 变成 head -> 5 -> 30 -> 20 -> null。
这种算法的好处就是简单,但缺点肯定很多,会带来严重的外部碎片,例如上图总空闲内存空间是 60,但想分配 40 个内存单位出来是不行的。再有是 CPU 竞争、缓存本地性等均未考虑到。
Segregated Lists
和 Free List 有点像,只是链表上存放的不是任意大小的空闲内存,而是固定大小的空闲内存。例如当系统中某种大小的内存块会频繁的分配和释放,那为这个大小的内存块专门维护一个空闲链表能加快内存分配和回收的速度,因为不需要什么策略去链表上前后查找、判断空闲内存大小和申请的大小是否匹配,而是找到空闲的内存块就能返回。此外还能减少内存碎片的数量。
这个分配方式的缺点是通用性比较差,不可能用这一种分配算法完全去满足整个系统各种工况下的内存分配要求,因为 List 数量不可能无限多。再有是 Segregated List 很可能会带来一定的内存浪费,这个有点类似于外部碎片但并不是严格意义上的外部碎片。例如有 64、128、256 三种内存大小的队列,当 128 的内存队列分配完毕了,再有申请 128 内存需求时候可能即使 64 或 256 队列内还有内存可分配也会再申请新内存去补充 128 大小的内存队列。因为想要去实现合并两个 64 的内存块或拆分一个 256 的内存块都会引入更多开销。例如竞争的开销,本来只用拿 128 队列的锁,为了完成拆分或合并又得去抢别的队列的锁。再有如果是做 64 的内存块合并的话需要维护 meta 信息在取出一块 64 大小的内存后立即判断出来这块内存前后的 64 字节内存是不是也在链表上,不然不能随意合并。拆分 256 大小的内存看上去很简单,但拆分后如果不实现合并机制的话就会让整个系统内存逐步向着拆分的更细碎,浪费更多空间的方向演进。总之都是费力不讨好,所以一般不太容易实现这种拆分合并机制。
这个算法还有个名字叫 Fixed-size Blocks allocation。它比较适合跟其它更通用的内存分配算法结合起来,只用于优化系统中某些特定部分的内存分配。例如在 Linux 等操作系统中使用的大名鼎鼎的 Slab Alloctor。Slab Allocator 是特殊的 Segregated List,它是专门为某种经常使用的 Object 维护的专用的 Free List。可以参看 Slab allocation - Wikipedia 。
Buddy Allocation
全称 Binary Buddy Allocator。Wiki 词条在 Buddy memory allocation - Wikipedia,Operating System: Three Easy Pieces 一书也有介绍。
先回到之前的 Free List 的机制,假设当前 Free List 上空闲内存是 head -> 5 -> 20 -> 30 -> null,现在想分配 35 个内存单位,从现有这个 Free List 是无法完成分配的,那假如 5 和 30 这两个内存块恰好是连在一起的,那将它俩合并就能满足分配要求了。可在找到 5 这个节点后只有遍历 Free List 后面所有节点才能知道跟 5 相邻的 30 也在 Free List,能合并后得到 35 个空闲内存单位。即 Free List 机制下,想找到相邻空闲内存做合并的复杂度是 O(n^2),不够经济。
于是就引入了 Buddy Allocation,它主要提供这么几个能力:
- 能快速判断相邻的内存块是否未分配;
- 相邻内存块如果未分配能快速合并成更大的连续的未分配内存块;
- 分配内存时大内存块能快速拆分成更小的可分配内存块;
核心点就如下图,Buddy Allocation 要求被管理的待分配内存必须是 2 的整数幂,例如下图待分配内存池就是 64KB。之后用树状结构将 64KB 的内存逐级拆分,深度每增加一层 Block 大小就减小一半但 Block 数量增加一倍。每个矩形块上标记的数字就是这个内存块当前最大能分配出去多少内存。
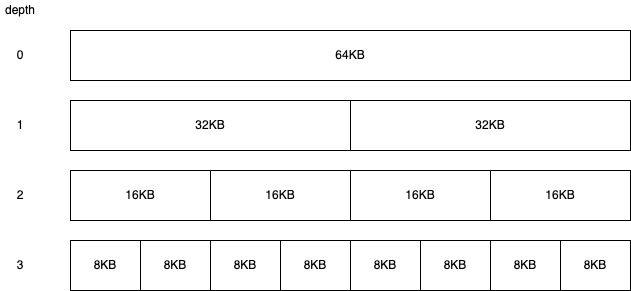
分配内存的过程就是从树顶部开始向下依次查找足够满足分配要求且最小的那个未分配的内存块。例如要分配的内存是 10KB,从树的顶部开始找,10KB 小于 16KB 但大于 8KB,所以只能用深度为 2 的第一块 16KB 的内存块来完成分配,分配后树变成:
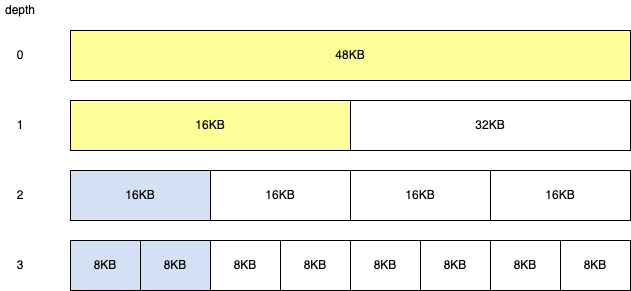
看到蓝色的部分是被分配出去的。深度为 2 的第一块 16KB 内存被分配出去后,相当于它的子节点也被分配出去。它的父节点在内存分配完后可分配内存数量也发生了改变,黄色是可分配内存数量发生改变的内存块。
如果蓝色的 16KB 内存块被释放,则可分配内存块又恢复到最初的有 64KB 可分配内存的状态。即从蓝色 16KB 内存块开始,每层都和自己的 Buddy 组合为更大的内存块,更新父节点可分配内存大小。
Buddy Allocation 最大的优势在于因为每个内存块都是 2 的整数幂,给定一个内存块地址只要改一个 bit 就能得到其 Buddy 内存块的地址,改一个 Bit 就能得到其 Parent 的地址。判断一块内存有没有分配出去也只需要给每个 Block 分配一个 Bit 就行,即最多需要 2^(depth + 1) 个 Bit 就能判断任意一个 Block 是否已经分配。有了这些能力后就能方便判断 Buddy 内存块的状态以及方便的做拆分合并。它的这个能力能够在释放内存时将释放的内存组合在一起变成更大的空闲内存,减少外部碎片的数量。同时又兼顾了分配内存时找到满足分配要求的尽可能小的内存块分配出去,减少内部碎片数量。
它的缺点主要是性能相对不高,每次分配、释放内存都有 O(logn) 的开销。此外因为需要维护每块内存是否分配出去,还有一定的维护开销。Block 拆分的越细,跨度越大也即 depth 越大,Buddy Allocation 总体开销也越大。所以它并不适合特别细碎内存块的分配管理。
有个有意思的地方是,回到上面的图,我们分配完 16KB 后,整个 Block 还剩余 48KB 内存可以分配。如果有个分配请求要求分配 48KB 的内存,这个 Block 看上去是能满足的,即将图中白色的剩余三个 16KB 内存都分配出去就行了。但一般来说不这么实现,主要是因为会增大记录每个 Block 是否分配出去的难度。例如这么分配出去三个 16KB 内存后就需要记录本次分配的是三个连续的 16KB Block,释放时候要将这三个 Block 都标记为释放,并且要更新他们三个的所有 parent。而如果不允许这么跨 parent 的分配的话,每次释放内存只用标记自己这个 Block 对应的分配标记,以及自己 Parent 的分配标记就好了。简单说就是同一个 parent 的 sibling 之间很容易计算对应地址,但跨 parent 计算 sibling 的地址就不容易了。
Jemalloc
实现内存分配的库有很多,c 标准库下的 malloc,ptmalloc,tcmalloc,还有今天打算多写一些的 Jemalloc。每一种分配器实现都有自己的侧重点,都有最适用的场景。它们的实现虽然细节上各不相同,但从大方向上来说都没有逃出前面介绍的各种内存分配算法范畴。而 Jemalloc 是因为实现上综合了前述各种分配算法,又比较出名所以拿来详细看看。看看实际中 Jemalloc 是怎么把 Buddy Allocation,Segregated Lists 等等细碎技术点结合起来实现一个高效的内存分配器的。
Jemalloc 是个通用的内存分配器,它最主要的目标就是在保证多核场景有比较好的性能情况下,尽可能的减小内存碎片、减少内存占用量。目前从网上一些资料来看被 Facebook、Firfox 等很多大公司在服务器上使用,开源的 Redis 默认在 Linux 上也是使用 Jemalloc 做分配器。
Jemalloc 的论文在这里,本节内容都来自这个论文。Facebook 也有个 Blog 介绍 Jemalloc 在这里。
按分配内存大小分类
Jemalloc 最基础的内存管理单元叫 Arena,每个线程都会唯一的绑定在一个 Arena 上,从指定的 Arena 上分配内存。如果机器上有多个 CPU,Jemalloc 默认也会分配多个 Arena,从而减小线程之间分配内存时的竞争。Jemalloc 就使用最基本的 Round-Robin 方式来决定每个线程该和哪个 Arena 进行绑定。为了实现简单和避免记录过多状态,Jemalloc 没有引入 Rebalancing 之类根据竞争状态重新将线程和 Arena 进行绑定的机制,即线程和一个 Arena 绑定后就不再改变这个绑定关系了。Round-Robin 方式下虽然可能出现某个 Arena 竞争激烈的问题,但总体平均下来经过测试这个开销在可接受范围。
Arena 分配内存会有两个层面,一个是 Arena 需要使用 sbrk 或 mmap 等系统调用从操作系统分配自己负责管理的内存。每次分配的内存叫 Chunk,一个 Chunk 在 Jemalloc 论文里默认是 2MB,一个 Page 是 4KB。另一个方面是应用需要去 Arena 上分配内存。Arena 会将自己从操作系统分配到的 Chunk 按内存大小分为 small, large, huge 几个大类,从而针对不同大小的内存分配请求来做定制优化。
应用分配内存时,需要先将请求的大小做元整,元整到最近的标准内存大小去分配内存。这种元整操作缺点是分配出去的内存会比实际申请的更大,有内部碎片。但优点也很多,例如如果是使用空闲链表来完成分配的话,维护空闲内存列表简单,并且内部碎片的问题可以通过划分更多粒度更细的空闲链表来解决。再有是分配时留有一定的余量,后续还能有一定的扩展余地,而不是要扩展重分配更多内存时就必须重新分配内存块。
举个例子,就好比我有个空闲内存链表,链表上内存块都是 512 字节,现在要分配 200 字节的内存,就将 200 字节元整到 512 字节直接从空闲链表上取一个 512 字节的内存块分配出去。好处是空闲链表维护简单,分配内存时也不用考虑 Best Fit 还是 First Fit,缺点是不经济,会有很高的内部碎片。上面分配的例子中有 312 字节的空间都成了碎片被浪费了。于是一个解决办法就是在 512 字节的空闲链表外再分出更多类型的空闲链表,如 128 字节,256 字节,512 字节各一个空闲链表。这样分配 200 字节内存时就只用元整到 256 字节,从 256 字节的空闲链表上取一个空闲内存块使用即可。内部碎片从 312 字节降低到了 56 字节。
而实际中,Jemalloc 对内存按分配大小做了更细粒度的划分,如下图所示:
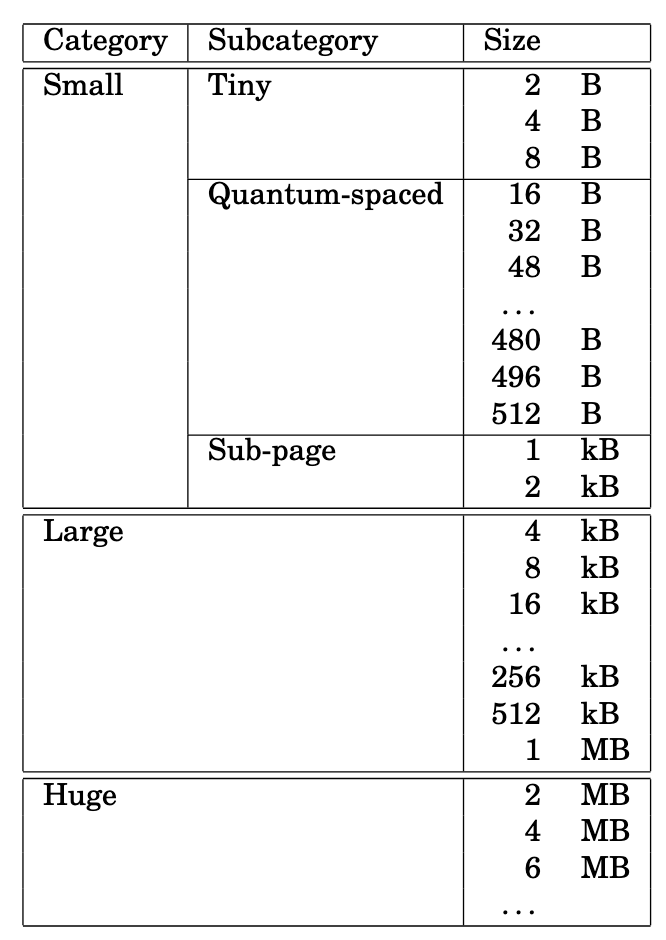
Huge 是大于半个 Chunk 的内存块,分配时直接分配独立的 Chunk 来完成分配。Metadata 用独立的红黑树来存储,存储的是哪个 Chunk 分配出去了,哪个 Chunk 没分配出去等信息。
如果待分配内存小于半个 Chunk 大于一个 Page 就归到 Large 一类。归到这个类的 Chunk 每个 Chunk 会使用 Buddy Allocation 的算法做切分,切到最小一个 Page 的粒度。上图中论文里默认认为一个 Page 是 4KB,所以 Large 大小对应的是大于 4KB 小于1M 的内存。一个或一个以上 Page 组成的内存块叫 Page Run。Chunk 下 Buddy Allocation 分配 Page Runs 的元数据存储在 Chunk 开头,称为 Page Map,即 Page Runs 和 Page Runs 的 Metadata 分开存储,不是例如每个 Page 的开头记录下来自己这个 Page 有没有分配出去等信息。好处是可以支持多个 Page 的完整分配,并且每个 Page 只有分配出去之后才会被操作,没被分配出去前,为了维护 Buddy Allocation 算法对 Metadata 的操作无需操作 Page。
Small 对应分配小于半个 Page 的内存。上图能看到 Small 又进一步细分为了三种 Subcategory。这么做主要是因为应用实际运行中,绝大多数分配、释放的都是超小的内存块,需要针对超小内存块高频分配和释放做特殊优化。
例如不对 Small 类别进一步细分的话势必会增大内部碎片的数量。进一步对 Small 进行细分会增大外部碎片的数量,但从实验来看,据 Jemalloc 的论文说减小的内部碎片数量会比增多的外部碎片内存量多。
除了对 Small 类型内存块进一步细分为三种 Subcategory 外,与 Large 类型内存块管理不同,Small 类型内存块不再用 Buddy Allocation 算法管理,而是每种大小类型的内存块用独立的空闲内存链表来管理空闲内存块。例如上图 2 Byte 内存会有一个独立的空闲链表,上面全挂着 2B 大小的空闲内存块。同样 16B 内存也有自己独立的空闲链表,上面挂着都是 16B 大小的空闲内存块。这么做的原因是 Buddy Allocation 在切分粒度特别细后,树的深度会很深,树上节点数量也会大幅度增加,Metadata 的开销也大幅度增加,查找空闲内存块的时间也会大幅度增加。例如一个 Page 是 4KB,按上图拆分到最小粒度是 2B,树的深度是 12,最差情况下要找一个空闲的 2B 空间需要从树顶开始一步步向下找才能找到空闲的 2B 内存块位置,很不经济。而使用固定大小的 Segregated Lists,则每个块都能用 Bitmap 上一个 Bit 来标记它是否有被分配出去,这样遍历 Bitmap 就能快速的查找未被分配的内存块。现在的计算机大多是 64 位的,即一次就能判断 64 个 Bit 对应的内存块是否分配出去,效率高很多。
如果不用 Buddy Allocation 只使用空闲链表,那也不合适。用空闲链表内的内存块如果大小不等,则需要引入 Best Fit、Last FIt 等查找可用内存块的算法,速度受影响。如果内存块大小相等,那又是需要为每种不同大小的内存块维护独立的链表,越大的内存块导致的内部碎片越多,浪费掉的内存越大。
那 Small 下既然都是用 Segregated Lists 为什么还要进一步分出来 Tiny,Quantum-spaced,Sub-page 三种大小呢?从前面图可以看到,Tiny 和 Sub-page 内队列之间差距都是 2 倍,但 Quantum-spaced 内队列之间差距都是固定的 16B。更细的拆分出来这三种大小实际就是为了拆出来固定间隔的 Quantum-spaced。按 Jemalloc 测试统计绝大多数情况下内存分配都是在 Quantum-spaced 内,所以这部分内存分配性能要好,并且可产生的内部碎片一定要小。拆分的细了能减小内部碎片。但如果全部都按 16B 这么拆分,从 2KB 到 2B 这么大跨度得拆出来上百个队列,又太多了。
惰性释放
无论是用来分配 Large 大小内存块的 Chunk 还是用来分配 Small 大小内存块的 Page Runs (一块或多块连续 Page) 都存在用完后需要分配新内存的情况。例如一个 Chunk 按 Buddy Allocation 算法做拆分后一直在这个 Chunk 上分配内存,但这个 Chunk 上内存总有被分配完的时候,分配完了就要再分配一个新的 Chunk 继续做切分做新的分配。但有的时候可能前一个 Chunk 还未完全分配完,只是没有足够的连续的内存空间,不得不再分配一个新的 Chunk。有了新 Chunk 后就能完成分配内存的要求,但如果这块新分配的内存很快就使用完毕要释放,释放后新分配的 Chunk 就成空 Chunk,按道理就得立即做释放,将 Chunk 占用的内存还给系统。这时候如果没有其它机制,可能会出现一个内存分配请求触发了新 Chunk 分配,随后内存释放又导致新 Chunk 释放,这么来回颠簸。所以得有个惰性机制,或者叫延迟分配和释放内存的机制来避免这个问题。
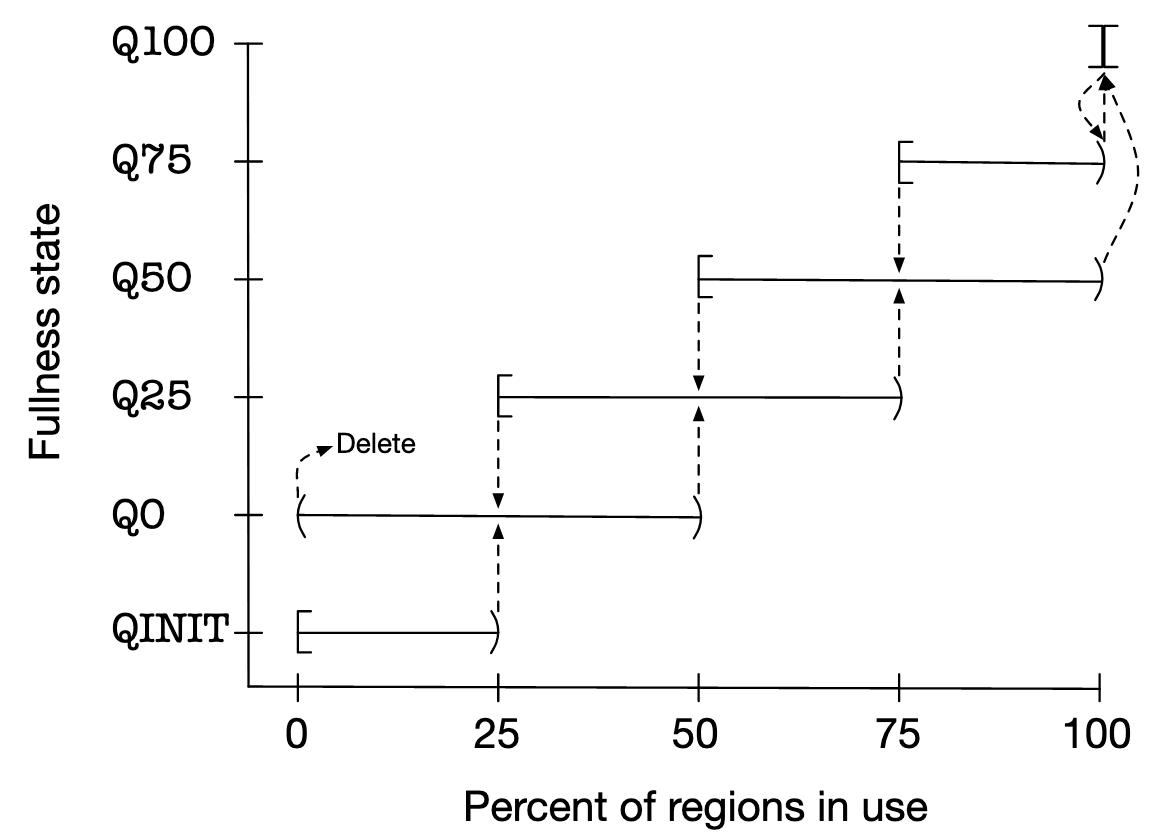
如下图所示,不管是 Chunk 还是 Page Runs,Jemalloc 都引入了这么 Fullness 状态的概念。拿 Chunk 举例,横轴 Percent of regions in use 就是这个 Chunk 已分配内存的占比(下图是按照 Page Runs 来叙述的,所以横轴写的是 Percent of regions in use,实际换成按 Chunk 来叙述也是一样的道理)。Arena 下按 Fullness state 分为 Q0, Q25, Q50, Q75, Q100, QINIT 几个队列。新分配的 Chunk 在使用率达到 25% 前会先放在 QINIT 下,到 25% 后会晋升到 Q0,使用率到 50% 后会晋升到 Q25,以此类推一直到 Q100。如果 Chunk 内内存释放,内存使用率下降,还能从 Q100 按照图中虚线指示逐步降回到 Q0,最终被 Delete。
每次有 Large 大小的内存要分配时,要按照 Q50, Q25, Q0, QINIT, Q75 的顺序在不同 Fullness 的队列内找符合要求的 Chunk,即先从剩余空间大的 Chunk 内找符合条件的 Chunk。 这么一来同一时间总有多个不同 Fullness 的队列存在,只有空间真的不够的时候才会分配新 Chunk。Chunk 内存释放后 Chunk 也不会立即被删掉,还是有个 Fullness 迁移的过程,逐步从 Q100 降低到 Q0 才删除。从而很难有前面例子中说的那种,分配一块内存就导致新 Chunk 分配,内存释放又立即导致 Chunk 释放的情况。
那有没有可能 Fullness 从 Q100 直接降回到 Q0 需要立即做删除的情况?Jemalloc 内存分配归类划分的比较巧妙,不会有这种情况出现。以 Chunk 为 2MB 为例,Large 大小的内存最大只会有 1MB,比 1MB 大的时候会按照 Huge 方式分配。所以即使释放最大的 Large 大小的空间,也最多是从 Q100 降低到 Q50,不会降低到 0。
那是不是能完全杜绝一个 Chunk 刚分配完又被释放的情况呢?也不是。例如初始分配一块内存恰好大于 Chunk 的 25%,这个 Chunk 分配后就会立即晋升到 Q0 队列。如果这块内存此时立即被释放,Chunk 也没有分配别的内存,那这个 Chunk 的内存使用率会降为 0,满足 Q0 清理 Chunk 的要求而被清理。即如果分配内存在 25% Chunk ~ 50% Chunk 之间,且分配后立即释放,有可能触发 Chunk 刚被分配出来又立即被清理的情况。
上面例子都按照分配 Large 大小内存的 Chunk 来说,但实际分配 Small 大小类型的 Page Run 也是相同的情况,也能用这套机制进行管理。
Jemalloc 优化总结
- 引入 Arena 减小多 CPU 同时分配内存时的竞争;
- 不同大小的内存采用不同的分配内存算法做优化;
- 引入惰性释放机制避免新分配的内存被过快释放,提高内存使用率;
按内存分配大小将管理的内存分为 Huge,Large,Small 三种类型,采用完全不同的分配策略管理三种类型内存的分配。
另外我们也能看到 Huge,Large,Small 到底按多大来划分肯定对性能有不小的影响,所以 Jemalloc 会提供各种配置在默认大小之外根据应用自己工况去修改 Huge, Large, Small 的划分,甚至 Tiny,Quantum-spaced, Sub-page 的划分。
Huge
特点:
- 分配次数少;
- 单次分配的内存块大;
- 分配和释放内存开销大;
优化办法:
- 用最简单的机制完全独立管理。不用考虑碎片,不用考虑回收内存复用,最小化 Metadata 维护。
Large
特点:
- 分配次数中等;
- 单次分配内存块大小中等;
优化办法:
- 用上 Buddy Allocation,通过自动合并减少内部、外部碎片量。
正是因为分配次数不会特别多,用 Buddy Allocation 才不至于让算法本身导致的空间、时间开销太过显著。也因为每次分配内存不会太小,所以减小碎片是主要问题。所以这个区间下的内存分配用 Buddy Allocation 会更合适。
Small
特点:
- 分配次数高;
- 单次分配内存块小;
优化办法:
- 用 Segregated Lists 减小内部碎片大小;
- 因为链表上每块内存一样大,所以能用 Bitmap 加快查询空闲内存的速度,加快内存分配速度;
Netty 下对 Jemalloc 的实现
背景信息
Netty 为什么要实现 Jemalloc ?
Netty 是 Java 程序,按道理会自动管理内存,但它还是自己实现了 Jemalloc 来管理内存。这里的原因说来话长,但简单说就是 Netty 作为高性能网络库,在收发数据时为了减少数据在内核和堆内存之间的拷贝需要大量使用堆外内存,而堆外内存的分配和释放开销较大。所以需要用 Jemalloc 来管理从系统分配来的内存,减少去系统分配内存的开销,提高内存使用效率。
Netty 的内存分配器分为堆内和堆外两种类型。堆内分配器就是在堆内分配内存的分配器,同理堆外分配器就是从堆外分配内存的分配器。刚提到堆外内存分配和回收开销较大,所以需要统一管理。但实际上堆内分配内存也用 Jemalloc 管理起来也能提高性能,降低 GC 压力。
Netty 实现的默认情况下,每个 Chunk 16M, 每个 Page 8K。它有四个核心类:
- PooledByteBufAllocator。即内存分配器接口,从接口上来分配内存;
- PoolArena。对应 Jemalloc 的 Arena
- PoolChunk。对应 Jemalloc 的 Chunk,完成 Chunk 的分配和 Buddy Allocation 的实现;
- PoolSubpage。完成 Small 类型内存的分配,实现 Bitmap 来查找空闲内存块的机制;
- PoolThreadCache。按线程维度对释放的内存进行缓存,提高性能;
PooledByteBufAllocator
初始化的时候,PooledByteBufAllocator 会根据当前 JVM 配置的最大使用内存大小和配置的 Chunk 大小计算出来要用多少个 PoolArena,初始化这么一组 PoolArena 出来。
PooledByteBufAllocator 提供了分配内存的接口,在 Netty 内部线程初始化的时候,就会为每个线程分配一个它所绑定的 PoolArena。后续这个线程使用 PooledByteBufAllocator 提供的接口分配内存的时候,就会从跟当前这个线程绑定的 PoolArena 上分配内存。
大致上可以理解为是如下代码:
ByteBuf newBuffer(int initialCapacity, int maxCapacity) {
PoolThreadCache cache = threadCache.get();
PoolArena<byte[]> arena = cache.arena;
return arena.allocate(initialCapacity, maxCapacity);
}
PoolArena
如前所述 PoolArena 是内存管理的入口,内存分配都靠 PoolArena 的 allocate 接口完成。
Huge 分配
待分配的内存如果特别大,超过一定大小后就会按照 Huge 方式分配。Netty 是分配内存大小大于一个 Chunk 时用 Huge 方式分配,而 Jemalloc 论文是大于半个 Chunk 就要用 Huge 方式分配。可能 Netty 是想减少 Huge 分配次数吧,没有找到依据。
分配和回收代码可以理解为:
void allocateHuge(PooledByteBuf<T> buf, int reqCapacity) {
PoolChunk<T> chunk = newUnpooledChunk(reqCapacity);
buf.initUnpooled(chunk, reqCapacity);
}
void free(PooledByteBuf<T> buf) {
PoolChunk<T> chunk = buf.chunk;
if (chunk.isHugeAllocated) {
destroyChunk(chunk);
}
}
其中 PooledByteBuf<T> buf 是指向分配出去的内存块的引用,分配完就用 buf 来使用分配出去的内存。看到关键点是:
- Huge 分配出去的内存是 Unpooled 会独占一个 Chunk,这个 Chunk 不是标准大小的,是跟申请分配内存大小一样;
- 分配出去的 Chunk 只被
PooledByteBuf<T> buf引用,Arena 内没有任何其它引用指向它; - 释放 Huge 内存时,首先会从 buf 内拿到 Chunk 的引用,再去调用 Arena 上的 free;
Normal 分配
分配小于 Chunk Size 又大于 Page Size 会用 Normal 方式进行分配。Normal 对应 Jemalloc 的 Large。Arena 下有 qInit, q000, q025, q050, q075, q100 等几个 Chunk 队列,叫 PoolChunkList,按 Chunk 内分配内存量占比缓存了当前分配过的所有的还未使用完的 Chunk。例如一个 Chunk 分配出去 80% 的内存,就会放在 q075 队列内。
分配内存逻辑如下,分配时按照之前说的以 q050, q025, q000, qInit, q075 的顺序查找曾经分配过的 Chunk 是否还有空间支持当前这个内存分配请求,能支持就用对应队列的 Chunk 完成分配,都没有找到合适的 Chunk 则会分配新 Chunk,并用新 Chunk 支持当前内存分配请求,将新 Chunk 加入 qInit 队列。
void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
if (q050.allocate(buf, reqCapacity, normCapacity) ||
q025.allocate(buf, reqCapacity, normCapacity) ||
q000.allocate(buf, reqCapacity, normCapacity) ||
qInit.allocate(buf, reqCapacity, normCapacity) ||
q075.allocate(buf, reqCapacity, normCapacity)) {
return;
}
// Add a new chunk.
PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize);
boolean success = c.allocate(buf, reqCapacity, normCapacity);
assert success;
qInit.add(c);
}
PoolChunkList 执行 add 方式如下:
void add(PoolChunk<T> chunk) {
if (chunk.usage() >= maxUsage) {
nextList.add(chunk);
return;
}
add0(chunk);
}
也就是说如果分配的内存特别大,例如将一个例如空的 Chunk 直接占满,这个空 Chunk 可以从 qInit 队列立即升级到 q100。
从 PoolChunkList 上分配内存时会遍历内部所有 Chunk,让每个 Chunk 判断是否能满足分配要求,能就用这个 Chunk 做分配,分配完后根据 Chunk 最新分配内存占比判断是否要移动这个 Chunk 到更高级的 PoolChunkList。例如 q075 的 Chunk 在分配内存占比增加到 100% 后挪到 q100。这块如下:
boolean allocate(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
if (normCapacity > maxCapacity) {
return false;
}
// 遍历所有 Chunk 尝试做分配
for (PoolChunk<T> cur = head; cur != null; cur = cur.next) {
if (cur.allocate(buf, reqCapacity, normCapacity)) {
// 能分配成功需要判断 Chunk 的分配内存占比是否超限,超限了要挪到
// 下一级 PoolChunkList
if (cur.usage() >= maxUsage) {
remove(cur);
nextList.add(cur);
}
return true;
}
}
return false;
}
释放内存逻辑和分配内存逻辑比较对称:
PooledByteBuf<T> buf内有引用指向自己这块内存属于哪个 Chunk,从而能去 Chunk 释放这块内存。- Chunk 释放完内存后,要根据 Chunk 内的引用找到它所在的 PoolChunkList,判断 Chunk 最新内存分配量占比是否下降到 PoolChunkList 的 minUsage,超过限制就要挪到上一级 PoolChunkList 去。
- 随着 Chunk 内存使用量的释放,Chunk 会最终被放入 q000 这个 PoolChunkList
- q000 队列没有上一级 PoolChunkList,在这个队列的 Chunk 如果使用量低于 q000 的 minUsage,就会触发 Chunk 的释放
- q000 的 minUsage 是 1%,但 Chunk 计算 Usage 时候特殊一些,只要还有内存没释放,内存使用量占比至少是 1%,不可能低于 1%
Tiny 和 Small 的分配
分配内存低于 512 字节时会用 Tiny 方式分配,分配内存大于 512 字节小于一个 Page 时按照 Small 方式分配,Page 默认大小为 8KB。之前 Jemalloc 介绍过,Tiny 和 Small 是用的 Segregated Lists 方式完成分配。
对于 Tiny 就是分成 16B, 32B, 48B, 64B, ... 512B 这样一共 32 个队列,分配低于 16B 的内存时就去 16B 这个队列去找空闲的内存块完成分配,分配 48B 到 64B 内存时候就去 64B 这个队列找空闲内存块完成分配。
对于 Small 默认 Page 为 8KB 时按 1KB, 2KB, 4KB, 8KB 一共分为 4 个队列,从 512B 开始向上元整。例如要分配 550B 则从 1KB 的队列内取一个 1KB 的空闲内存完成分配。其它大小以此类推。超过 8KB 一个 Page 则就不是 Small 分配方式了。
Arena 下不管是 Tiny 还是 Small 的队列,队列内元素都是 PoolSubpage 类对象,区别只是每个 PoolSubpage 的大小不同。大致示意图如下,负责 Tiny 大小的 PoolSubpage 链表队列一共有 32 个,链表的 Head 是个哑元存放在 Arena 的 tinySubpagePools 字段下。同理 Small 大小的 PoolSubpage 链表队列一共有 4 个,Head 存在 Arena 的 smallSubpagePools 字段下。
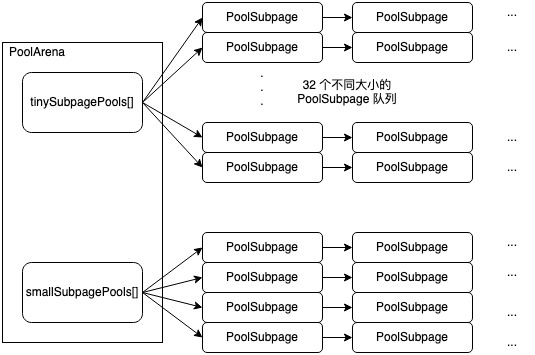
以分配一个 1KB 的内存为例,分配时首先根据 1KB 计算得到这个大小属于 Small 类型,并且是 smallSubpagePools 上 index 为 3 的 PoolSubpage 队列负责分配,于是找到这个队列的 smallSubpagePools[3] 引用的 PoolSubpage 判断这个 PoolSubpage 是否有 next 节点,有的话则就用 next 指向的 PoolSubpage 完成分配。没有则要分配一个新的 PoolSubpage。
PoolSubpage 不实际做内存分配,内存分配还是在 PoolChunk 上。当要分配一个新的 PoolSubpage 时,实际就是走 Normal 的内存分配流程,分配出一个 Page 8KB 的内存出来供新的 PoolSubpage 引用。上面例子中,我们要分配的内存是 1KB,新分配的内存是 8KB,于是将 8KB 在新分配的 PoolSubpage 内拆成 8 份维护起来。再将新的 PoolSubpage 插入 smallSubpagePools[3]指向的 PoolSubpage 链表的表头。最终在这个新 PoolSubpage 上完成 1KB 内存的分配。
当一个 PoolSubpage 内维护的空闲内存块全部被分配完毕了,这个 PoolSubpage 会从上述链表上移除。相应的,在有空闲内存块被释放后,这个被从链表上移除的 PoolSubpage 需要重新加回到链表当中。一些关键点:
- PoolSubpage 链表上除了头结点外,其它 PoolSubpage 一定有空闲内存块存在;
- 每次分配空闲内存的时候,都会从头结点指向的下一个 PoolSubpage 分配空闲内存块;
- 因为 Arena 会被多个线程共享,多个线程可能都在分配相同大小的内存,所以对 Tiny 和 Small 类型的分配来说锁加在 PoolSubpage 头结点上,不同大小的 PoolSubpage 分配时没有竞争;
PoolChunk
前面提到过,实际内存都是按 Chunk 分配的,即使是 Tiny 或 Small 类型的内存分配,也是每次从一个 Chunk 中分配出一个 Page 的内存再加以拆分得到 PoolSubpage 后完成分配。所以 Chunk 是内存分配和管理的核心。
PoolChunk 实现了 Buddy Allocation 来管理内存。一个 Chunk 默认是 16M 大小。回顾上面对 Buddy Allocation 的介绍我们知道它是将一块内存像二叉树那样组成,深度为 0 时是 16M,Chunk 内最小分配单位是一个 Page 8KB,所以这棵树叶子节点代表的大小就是 8KB 所以树的深度最大是 11,复用之前的示意图如下,图中叶子节点数量为 2048 个,非叶子节点数量一共 2047 个一共 4095 个节点:

这棵二叉树在 Chunk Size 和 Page Size 固定后节点数量就不会变,为了紧凑的表达出这棵树我们用数组来做。每个节点都有个从 1 开始的唯一 ID,数组的 index 就是 ID,数组的 Value 是对应节点在二叉树上的深度。为了计算方便且我们只有 4095 个节点需要记录,所以跳过数组内 0 这个 index。于是得到的数组为:

这种表示方法除了紧凑外还有个计算上的好处,这些快捷计算方法对 Buddy Allocation 尤为重要:
- 根据节点的 ID 能立即算出来它 Parent 的 ID 或 Child 的 ID。例如 ID 9 我们立即知道它的 Parent 是 9 / 2 = 4。Child 是 9 * 2 = 18 和 19。
- 根据节点 ID 能立即算出来它的 Sibling 的 ID。例如 ID 9,9 XOR 1 = 8 就是它的 Sibling。
- 给定一个深度,能很快计算出来这个深度起始 ID 是什么。例如要找深度是 3 的起始 ID 就是 2^3 = 8。
这样的数组在 PoolChunk 下有两个,一个叫 deptshMap,只用来根据 ID 快速的得到它对应的深度,是个 Readonly 的变量,不会做修改。另一个叫 memoryMap 则是用来标记给定的 ID 对应的节点到底有多少连续的内存空间能够分配出去。
例如初始时 ID 是 9,memoryMap 内对应值是 3,表示 16M / (2 ^3) = 2M 的内存能够分配。如果 9 这个 ID 对应的内存块被分配出去,则要修改 memoryMap 内 9 对应的深度为 12 ,因为最大深度是 11,所以 12 被当做一个不可能出现的值用来表示这块内存已经没有剩余空间可分配。9 被修改了,9 的 Parent 节点 4 也得做修改,因为前面说了 memoryMap 上的 value 是这个节点能连续分配的最大内存大小。9 被分配出去后,4 这个节点原来能分配出去 4M 的内存,现在只能分配出去 2M 的连续内存了。而这个 2M 的连续内存来自于 9 的 Sibling 8,也就是说将 4 的值修改为 9 的 Sibling 8 的深度值。之后还要将 4 的 Parent 2 的值也更新为 8 的深度值。2 的 Parent 1 也更新为 8 的深度值。
于是分配内存的算法就出来了:
- 对待分配内存大小做元整,计算出分配这块内存的深度是多少。例如要分配 1.5M 的内存,得到满足分配条件的内存块是 2M,对应深度为 3;
- 从二叉树顶开始向下查询每个节点在 memoryMap 的深度是否小于目标深度,小于则判断是当前节点的左子树小于目标深度还是右子树小于目标深度,从而决定是走左子树还是走右子树;
- 当前二叉树节点在 memoryMap 的深度等于目标深度后,将当前节点在 memoryMap 的深度值设置为 12;
- 从当前节点开始一路向树顶开始更新 memoryMap 内的深度值,更新方法是判断左右两个子节点在 memoryMap 里谁更小,更新当前节点值为小的那个值;
- 返回之前找到的深度符合要求的节点 ID
后续拿着节点 ID 就能找到对应内存块在 Chunk 上的 Offset 去使用这块内存。
内存释放则相对简单的多:
- 释放内存时候一定有这块内存在 Chunk 内对应的 ID,根据 ID 用 depthMap 计算出这个 ID 原本的 Depth 是多少;
- 在 memoryMap 内将对应 ID 的深度值设置为 depthMap 内原本的深度值;
- 从对应 ID 开始递归的一路更新它的 Parent 在 memoryPath 内的深度值。更新方法和分配时很相似,一个是比较两个 Child 的深度值,取小的那个设置为 Parent 的深度值。如果两个 Child 都被释放了,则 Parent 的深度值要设置为 Child 深度值 - 1
看到这里我们就明白了 Buddy Allocation 的实现。之前看 Buddy Allocation 算法时候还想的可能要合并拆分 Sibling 之类的,实际都没有这些操作,就一个 memoryMap 记录分配后的深度就搞定了。
另外看这块代码时候有几个默认常量需要记一下,有的之前也提到过。即 Page Size 默认是 8KB,Chunk Size 默认 16MB,maxOrder 是 11,Page Shifts 是 13。Netty 代码里有大量的位运算,不记着这些常量一会可能就晕了。也正因为位运算太多,我们这里只记录算法,不再把详细代码贴出来了,实际算法拎出来后再看代码就容易多了。
PoolSubpage
前面介绍 Tiny 和 Small 类型内存分配时介绍了 PoolSubpage 是如何分配出来的。我们知道一个 PoolSubpage 对象做的事情就是将一个 Page 大小的内存块拆分为很多指定大小的内存块,并在内部维护这些内存块的空闲链表,能快速的找到哪个内存块是分配出去的,哪个是没分配的。
因为单个 PoolSubpage 管理的内存块都是固定大小的,所以它内部用 Bitmap 来标记每个内存块的分配状态,一个 Bit 就对应一个管理的内存块,Bitmap 用 Long 数组来实现,所以遍历这个 Long 数组时判断一个 Long 元素就能判断出对应的 8 个内存块里是否有空闲的内存块可用。
遍历 Bitmap 查空闲内存块都比较简单,不多记录。相对有意思一点的是 PoolSubpage 里维护了一个 nextAvail 的变量,作用是快速查找 PoolSubpage 内可用的空闲内存块。当这个变量存在值的时候,分配内存时就直接返回这个变量值,不存在时就走遍历 Bitmap 的逻辑。
private int getNextAvail() {
int nextAvail = this.nextAvail;
if (nextAvail >= 0) {
// this.nextAvail 只能用一次,用完完成分配就得置为无效
this.nextAvail = -1;
return nextAvail;
}
// 这里会去遍历 Bitmap 找空闲内存
return findNextAvail();
}
this.nextAvail 只有在明确知道某个内存块一定空闲时才会设置。一个是初始化完成后,它会设置为 0,因为第一块内存块一定是空的。再有是有内存块被释放后,会立即设置为这个刚被释放的内存块的 index。遍历 Bitmap 的时候因为找到一个空闲内存块后就直接返回这个刚找到的空闲内存块了,不会再找下一个空闲内存块,所以遍历 Bitmap 时候不会再设置这个 nextAvail 值。
这样能相对减少一些遍历次数。
并发安全
前面提到过,进程内会有多个 PoolArena,每个线程会和一个 PoolArena 绑定,从指定的 PoolArena 上分配内存。从而去降低对单个 PoolArena 的竞争。在 PoolArena 内则是通过锁来保证并发安全。
对于 Huge 分配 PoolArena 不需要加锁,每个 Huge 分配都是独立的,线程之间没有竞争。
对于 Normal 来说,因为内存会在 Chunk 内分配,Chunk 内的二叉树结构是非并发安全的,另外 Normal 分配还可能新增 Chunk 到 q000, qInit 等队列,所以 Normal 分配方式会加个大锁到 PoolArena 上。因为 Normal 分配相对较少,所以竞争也不会特别激烈。释放内存时候也类似,发现释放的内存曾经是 Normal 方式分配的,那释放时候需要拿 PoolArena 上的大锁。
对 Tiny 和 Small 来说,锁是加在每种大小的 PoolSubpage 链表队列的哑元 Head 上。通过减小锁的粒度减小了竞争。释放锁时也是抢对应的 PoolSubpage 链表队列的 Head 上的锁。
PoolThreadCache
从并发安全分析来看,Netty 实现的内存分配器锁已经比较少了,能比较好的控制线程之间的竞争。但为了能进一步避免竞争,以及为了更好的 Cache Locality 亲和性,又引入了 PoolThreadCache 这么个线程私有的内存缓存。做的事情简单说就是每个会分配内存的线程都用 PoolThreadCache 将自己释放的内存先缓存在 PoolThreadCache 不直接交还给 PoolArena,在下次分配内存时优先从 PoolThreadCache 内分配,没有可用的内存时才会去 PoolArena 分配。
Huge 分配不用管,PoolThreadCache 只负责缓存 Tiny,Small,Normal 三种类型的内存。Tiny Small 比较好说,分配内存大小提前都知道,PoolThreadCache 会为每种大小的内存块都单独用个缓存队列来维护,不同大小的内存放在不同的队列内。Normal 的稍微特殊一些,但原理也差不多,即将 Normal 分配的内存大小按不同大小进行归类,放在不同的队列里。分配内存时对分配请求的内存大小做元整,整理到标准大小后在对应的缓存 Normal 内存块的队列内找空闲内存。
PoolThreadCache 比较 Trick 的地方在于不能缓存太多内存块,一个线程缓存了内存块后就表示这块内存被这个线程独占,其它线程无法访问到这块内存。如果这个线程用不了那么多内存,就会导致整个系统内存使用量升高。
PoolThreadCache 的做法是每次从回收的内存缓存里分配内存时都将一个计数加一,当计数达到一定次数后就触发 trim 操作,Tiny,Small,Normal 等每种大小缓存队列全部会做一遍清理。各缓存队列清理的方法不太好描述,大概看一下吧,总之个人认为是个比较简单的清理策略。
public final void trim() {
// size 是缓存队列最大限制长度
// allocations 是过去一个 trim 周期从这个缓存队列上分配出去的内存块数量
int free = size - allocations;
allocations = 0;
// 大致上相当于每个 trim 周期都做一次统计,统计上个周期实际分配内存块数量
// trim 时只保留这么多的内存块数量在缓存中,多余的都清理掉
if (free > 0) {
free(free, false);
}
}
参考
- 介绍 Jemalloc 的视频:https://www.youtube.com/watch?v=RcWp5vwGlYU&list=PLn0nrSd4xjjZoaFwsTnmS1UFj3ob7gf7s
- Jemalloc 论文:https://people.freebsd.org/~jasone/jemalloc/bsdcan2006/jemalloc.pdf
- Jemalloc 在 Github 的 Wiki Background · jemalloc/jemalloc Wiki · GitHub
- Jemalloc 官网 jemalloc
- TCmalloc 是 Jemalloc 之前的一个内存分配器,主要是用 Thread-Cache 来减少竞争,这部分 Jemalloc 也有做,所以只是大概看了一下介绍TCMalloc : Thread-Caching Malloc
- 有一些关于 Jemalloc 如何做内存缓存的内容 Scalable memory allocation using jemalloc - Facebook Engineering
- 有一些 Jemalloc 的基本内容,也有跟其它一些内存分配器的对比Basic understanding of jemalloc
- 各种内存分配器的对比 Testing Memory Allocators: ptmalloc2 vs tcmalloc vs hoard vs jemalloc While Trying to Simulate Real-World Loads - IT Hare on Soft.ware