设计原则
Google 几个观察到的现象:
- 要存的文件越来越多,越来越大
- 存储文件的系统规模越来越大,机器越来越多。机器出错、损坏已成为常态
- 大多数数据写入都是 Append 模式,而不是 Overwrite
- 多数系统对一致性要求并不那么高
根据这些现象,GFS 勾勒出自己的设计目标:
- 需要用大量的容易出问题的但便宜的机器组成系统。要求系统有很好的容错性
- 存储的单个文件都很大,至少 100MB 以上,大多数几个 GB。小文件要支持但不做优化
- 读取操作由大量的单个 Client 读数 MB 数据的顺序读和少量随机读组成
- 写操作也是大量的大数据量的顺序写,和少量的随机写组成
- 必须支持高并发。尽可能减少同步和原子操作。
- 吞吐量相对延迟来说要求更高。即能在延迟上做妥协来换取更高吞吐量
由设计目标得到了设计原则:
.jpg)
简单
简单这个设计原则引出了三个关键设计点:
- 单 Master
- 照着 Linux 文件系统设计 API
- 用 Linux 文件系统存文件
- 弱一致性保证
前三个设计原则让 GFS 架构大幅度简化。它主要需要解决的问题是 Master 的高可用,所以设计了Checkpoints、Operation Logs、影子 Master(Shadow Master)、Supervisor 等一系列的工程手段,来尽可能地保障整个系统的“可恢复(Recoverable)”,以及读层面的“可用性(Availability)”。
除了架构上精简外,GFS 的一致性相当宽松。GFS 本身对于随机写入的一致性没有任何保障,而是把这个任务交给了 GFS 的客户端和上层应用。GFS 称这种设计方式为 「co-designing the applications and the file system API」。对于 Append 操作,GFS 也只保障 At Least Once。
GFS 是一个基本没有什么一致性保障的文件系统。但即使是这样,通过在客户端库里面加上校验、去重这样的处理机制,GFS 在大规模数据处理上已经算是足够好用了。
优化硬件带宽使用
大规模文件系统主要受硬盘、网络带宽两个方面的硬件水平的限制,GFS 需要对这两个瓶颈做设计。
硬盘方面,论文发出的年代都在使用机械硬盘,随机读写性能很差,所以 GFS 的设计都是注重顺序读写性能,对随机写入的一致性甚至没有任何保障。
网络带宽方面,当时的数据中心,机器网卡普遍是百兆卡,网络带宽会是 GFS 这种分布式文件系统的瓶颈。GFS 在写数据的时候,选择了链式的数据传输方式,客户端传个 Server A,传完后 Server A 再传给 Server B,Server B 再传给 Server C,而没有选择树形的数据传输方式,即客户端直接传输数据给 Server A,B,C,或者由客户端传数据给 Server A 再由 Server A 传给 B C。原因主要是为了更好的利用客户端以及单个服务器的带宽。树形传输方式虽然理论上延迟更小,但占用带宽高。
此外 GFS 复制数据时候采取收数据的同时就立即转发数据到下一个副本,充分利用上下行带宽。
为了减少网络带宽,GFS 在复制文件时候是使用专用的 Snapshot 的指令做文件复制。在文件复制的时候直接发送 Snapshot 指令给服务器,完成数据在服务器之间的复制,而不是数据先下载到客户端再传给另一个 Server,也是为了减少数据在网络上传输。
单 Master 设计
GFS 的架构最重要的是这张图:
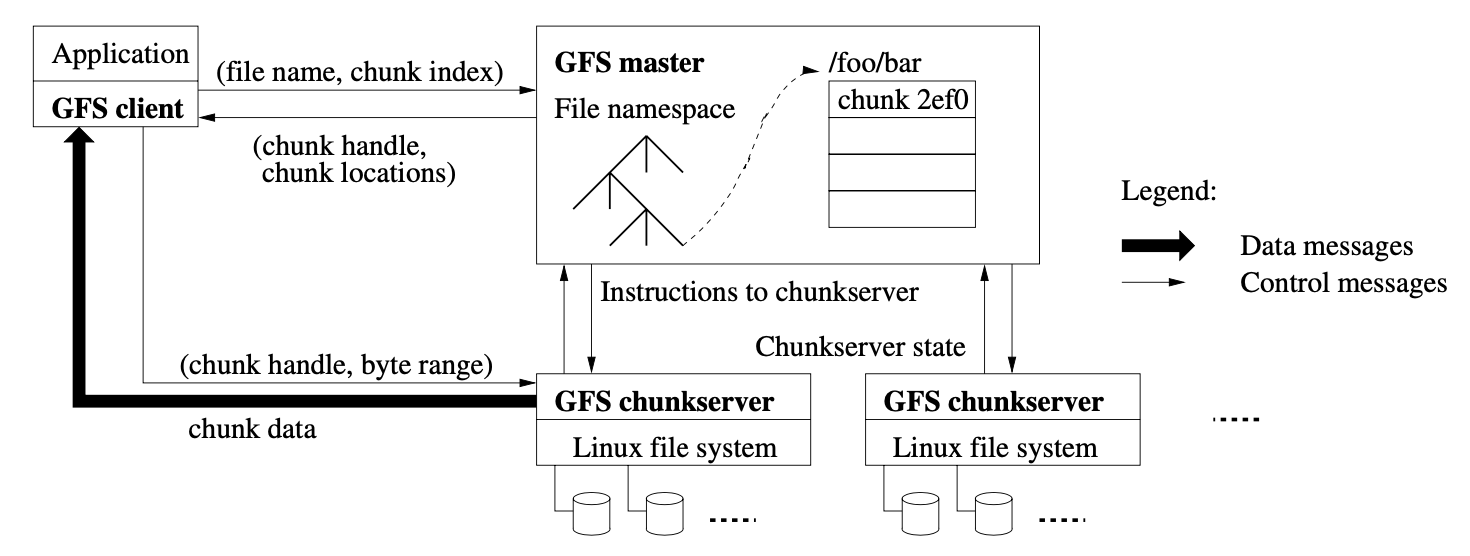
大致上看到 GFS 一共有三个部分:
- Master
- Chunkserver
- Client
GFS 上的文件会按固定 64MB 大小拆分为多个 Chunk,每个 Chunk 不可变,且会由 Master 分配个唯一的 64bit 的 Chunk Handle 作为唯一标识。每个 Chunk 会在多个 Chunkserver 上存储,从而避免一个 Chunkserver 宕机而导致不可用。默认情况下,每个 Chunk 会有三个副本。Chunkserver 是普通 Linux 服务器,跑着 GFS 的 Chunkserver 程序。Chunk 的多个副本会分为 Primary 和 Secondary,数据不一致的时候以 Primary 为准。除了提高可用性外,多副本还能提高读取能力。
Chunkserver 就使用普通的 Linux 文件来存 Chunk,每个 GFS 文件在 Chunkserver 上也对应一个普通的文件,从而复用 Linux 文件系统的 Cache、Buffer 机制,将频繁访问的数据放在内存,不需要再设计实现。
每个 Chunk 在 Chunkserver 上都是独立的文件,一个 GFS 文件因为由多个 Chunk 组成,所以 GFS 单个文件的数据会散布多个 Chunkserver 分散存储。
从图上能看到,GFS Client 和 Application 绑在一起,App 使用 GFS Client 和 GFS Master、GFS Chunkserver 通信。服务内数据流和控制流分开,GFS Client 和 GFS Master 通信都是控制指令,GFS Client 的数据流则直接是和 Chunkserver 交互。
图上还有很多细节,下文会叙述。先只看 Master。一个集群只有一个 Master,Master 有以下几种身份:
- 相对于存储数据的 Chunkserver,Master 是一个目录服务;
- 相对于为了快速恢复数据的 Backup Master,它是一个同步复制的主从架构下的主节点;
- 相对于为了保障读数据的可用性而设立的 Shadow Master,它是一个异步复制的主从架构下的主节点。
除此之外,从论文来看 Master 还要负责 Chunk Lease 管理,定期清理 Orphan chunk,在各个 Chunkserver 间调配 Chunk。Master 要定期给 Chunkserver 发 Heartbeat,一方面是下发指令,另一方面是收集 Chunkserver 状态。
单 Master 的好处感觉归结下来就是,简化 File 和 Chunk 的管理。包括 Chunk 分配,Chunk 复制,Chunkserver 可用性保障,维持 Chunk 的副本,文件管理等。Master 上单机存储集群上所有 File 和 Chunk 的信息,就能简化上述功能的实现。例如我们要保障一个路径下不能有同名文件,如果 Master 不是单机的则实现难度将大增。
单 Master 的缺点就是 Master 容易成单点,影响性能和可靠性。
Master 作为目录服务
对应 HDFS 的 Name Node,每个文件都有自己的路径,就和 Linux 文件路径很像,由命名空间 + 文件名来唯一的确定一个文件。
Master 会为每个 Chunk 选一个 Primary Chunkserver,并会给 Primary 颁发 lease。在 lease 期间,Primary Chunkserver 一般不会变化。Master 会定期通过 Heartbeat 将 Primary Lease 延期。当 Primary 宕机后,Master 会再选一个 Primary。
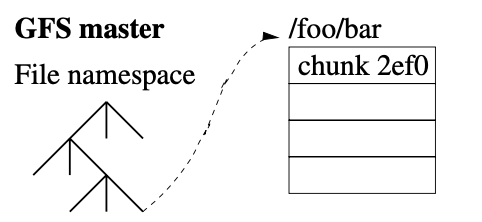
下图是为了说明一个文件由多个 Chunk 组成,每个 Chunk 在三个 Server 存储,一主俩从。
(1).jpg)
Master 存储信息如下:
- 命名空间和文件信息。包括文件的 Access Control 信息
- 文件有哪些 Chunk,看到下图 Chunk 有个唯一 ID,如 2ef0
- 每个 Chunk在哪个 Chunk Server 存储
前两个信息 Master 都是持久化方式维护,每次有操作都会先写 Operation Log 到磁盘,还会备份到远程服务器。从而保障 Master 宕机后恢复出来的还是一致的数据。写磁盘后数据不丢。
但是 Chunk 在哪个 Chunkserver 维护,这个是 Chunkserver 每次加入 Cluster 后上报给 Master 的。Master 每次重启也会问所有 Chunkserver 要这个数据。Master 只在内存维护这个信息。好处是 Chunk 本身就是 Chunkserver 维护的,只有 Chunkserver 最清楚自己存了哪些 Chunk。集群大了以后 Chunkserver 又很容易出问题,所以上述定时上报的机制相当于定时做校正,让 Master 真的能正确维护 Chunk 所在位置信息。
访问数据步骤:
- 客户端根据待读取文件名和 Offset 和 Length 去 Master 确定要读的数据在哪些 Chunk,这些 Chunk 在哪些 Chunk Server。随后客户端会 Cache 住 Master 返回结果,用文件名和 Chunk Index 为 Key (Chunk Index 就是根据 Offset 和固定的 Chunk 大小算的 Chunk Index)
- 客户端带着 Chunk Handle 和 Byte Range 去 Chunk Server 完成数据读取。一般是选离自己最近的 Chunk Server 做读取。
- 后续客户端要还有数据要读,就不再跟 Master 做交互,直接从自己 Cache 里找到 Chunk Server 信息,跟 Chunk Server 做交互。一般第一步访问 Master 时候就会将待访问的 Chunk 之后的 Chunk 的信息也多返回一些,减少客户端和 Master 的交互。
为了避免 Master 成为瓶颈,有几个优化:
- Master 内的数据都在内存有一份。避免读磁盘,从而提高性能
- Master 存储的数据能在客户端做缓存。因为文件 Meta 也不经常变化
- Master 内数据尽可能精简。每个 Chunk 在 Master 内的数据不超过 64 字节,每个文件维护的 Namespace 信息通过 Prefix Compression 后也不超过 64 字节。
Master 把数据都存在内存还有个好处,就是 Master 能快速的定期对所有 Chunk 做轮询,从而完成一些定期操作。例如将 Orphan Chunk GC,以及根据 Load 或磁盘使用情况对 Chunkserver 做负载均衡等。
Master 数据恢复机制
因为 Master 数据都放内存,Master 一旦宕机目录树信息就没了。为了快速恢复,引入了:
- Checkpoint 机制
- Backup Master 机制
- Shadow Master 机制
Checkpoint
前面提到过,Master 上所有对 Metadata 的操作都会记录 Operation Log。这个 Log 非常重要,所以 Master 每次有 Metadata 变更操作,都必须等 Operation Log 在本地和远程都同步写成功后,才能给客户端返回操作成功。Master 会将 Operation Log 做 Batch,批量写入。
Operation Log 一方面是保障 Master 上对 Metadata 的修改能持久化,不会丢。另一方面是决定了对 Metadata 并发操作顺序。后面会提到,GFS 决定并发变更次序就得依靠这个的顺序。
Master 重启恢复状态时候就是 reply 所有 Operation Log。为了减小 Startup Time,Operation Log 尽可能小。此外,Operation Log 数量达到一定程度,就要生成 Checkpoint,减少重启后需要 Reply 的 Operation Log 数量。只 Reply Latest Checkpoint 之后的 Operation Log 即可。
Checkpoint 是内存的一个直接映射,不需要额外的处理就能构建内存模型,从而加快 Master 恢复速度。
生成 Checkpoint 可能比较耗时,所以都是后台进行。生成好之后直接做切换,切换到新的 Checkpoint 以及新的 Log File。Checkpoint 生成也需要在 Local 和 Remote 都存好后才能做切换。Checkpoint 生成完后,老的 Operation Log 和 Checkpoint 可以删除,但为了避免严重故障时数据无法恢复,所以老 Checkpoint 还是会保留一段时间。
这里 Local 指当前 Master,Remote 指下面要说的 Backup Master。
Backup Master
Backup Master 和 Shadow Master 示意如下:
.jpg)
即每次 Master 写入,需要同步的写入 Backup Master,只有操作在 Master 和 Backup Master 都写入成功,操作记录刷写到磁盘,才算写 Master 成功。这就是前述 Operation Log 写入机制,必须在 Local 和 Remote 都写成功才算成功。
此外有个 Supervisor 服务监控 Master 是否在运行,当 Master 进程挂掉,Supervisor 立即重启 Master,并选个 Backup Master 升级为 Master。(这里有个疑问,切换到 Backup Master 后,整个系统将是单点 Master 状态,原来的 Master 启动之前,如果没再有一个 Backup Master 的话,GFS 的 Master 将无法写入)
客户端或 GFS Server 通过 DNS 的 CName 来访问 Master,Supervisor 改掉 DNS 记录后,客户端或 GFS Server 就切换到新的 Master。
Shadow Master
Supervisor 从感知到 Master 宕机,到切换到新 Master 虽然能做到快速恢复,但还是会要一些时间,在此期间 Master 不存在还是会导致大量客户端请求失败。解决办法是 Shadow Master,前面写过是异步复制的,Shadow Master 没写入能力,也不晋升到 Master,只在 Master 宕机后提供读能力。
Shadow Master 同步的是 Master 的 Operation Log,将 Operation Log 按次序 Apply。并且 Shadow Master 也需要定期跟 Chunkserver 通信,获取 Chunkserver 的数据,因为 Chunk 在哪些 Chunkserver 维护,这个信息在 Chunkserver 上。只是 Shadow Master 同步频率要低。
Master 宕机感知
Master 是否宕机得有个外部服务来感知,要是这个感知机制失效,就容易出现脑裂之类的问题,导致数据出现不一致。
GFS 的 Master 如何监控在 GFS 论文里没写,但在 Chubby 的论文里有提。可以参看 Chubby 的论文:
The Chubby lock service for loosely-coupled distributed systems
此外,HDFS 的一些介绍文章也写的 NameNode 需要有类似 Chubby 的东西来监控,例如奇数个 JornalNode 组成的 Cluster 或者用 Zookeeper。例如这里介绍的 Hadoop HA 策略:
GFS 完整架构
在有了 Backup Master、Shadow Master、Supervisor 后,整个 GFS 的架构包括:
- GFS Client。用来和 Master、Chunkserver 交互
- Chunkserver。用来存实际文件数据
- Master。用来维护文件目录信息,维护 Chunk 在各个 Chunkserver 的调配
- Backup Master。用来作为 Master 的副本,保障数据不要丢
- Shadow Master,在 Master 宕机后支持对 Master 数据的读取
- Supervisor。监控 Master,Backup Master 的运行状态,感知 Master 健康状态,在 Master 宕机后切换到 Backup Master
针对磁盘访问做优化
这个没有特别能讲的,主要是 GFS 论文出来的时候磁盘还是 5400 转 7200 转机械磁盘为主,随机读写能力差,就导致 GFS 设计之初就是为了顺序读写而生的,尽力优化数据顺序读写场景,因为随机读写再怎么优化不可能超过物理瓶颈极限。
现在即使进化到了 SSD,顺序写也比随机写快很多。顺序写依然有优势。
针对网络瓶颈做优化
在介绍对网络瓶颈做的优化前,需要先看看 GFS 写数据的流程。GFS 不是靠在读取中做什么特殊的动作,来保障客户端读到的数据都一样。“保障读到的数据一样”这件事情,是在数据写入的过程中来保障的。
首先需要看 GFS 写数据的过程如下图。
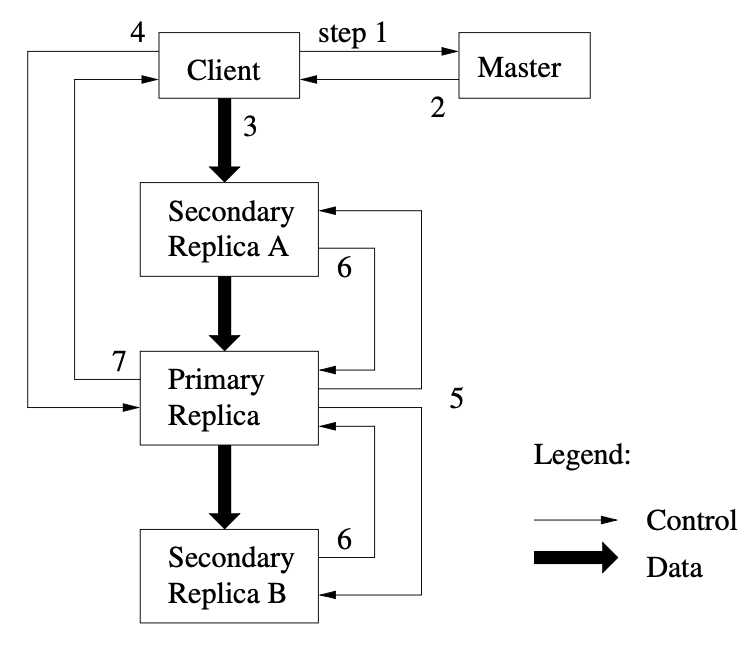
- 读 Master,获取目标文件所在 Chunk Server
- 返回 Chunk Server 地址,包括哪个 Chunk Server 是 Primary 哪个是 Secondary,客户端也会 Cache 这些信息,直到缓存的 Primary 无法访问或者 Primary 说它自己不是 Primary。
- 客户端找个离自己最近的 Chunk Server,发送数据过去。Chunk Server 不实际写数据,先只把数据放 LRU 缓冲里,直到这个数据写入磁盘或超时
- 数据传至最近次副本后,客户端就会发送一个写请求给到 Primary。因为 GFS 面对的是几百个并发的客户端,所以 Primary 可能会收到很多个客户端的写入请求。Primary 自己会给这些请求分配 Serial Number,确保所有的数据写入是有一个固定顺序的。接下来,Primary 就开始按照这个顺序,把刚才 LRU 的缓冲区里的数据写到实际的 chunk 里去。
- Primary 会把对应的写请求转发给所有的次副本,所有次副本会和主副本以同样的数据写入顺序,把数据写入到硬盘上。
- 次副本的数据写入完成之后,会回复主副本,我也把数据和你一样写完了。
- 主副本再去告诉客户端,这个数据写入成功了。而如果在任何一个副本写入数据的过程中出错了,这个出错都会告诉客户端,也就意味着这次写入其实失败了。
上面有个有意思的地方,全局来看,变更次序首先是由 Master 选 Primary 决定。其次是由 Primary 上给每个变更分配的 Serial Number 来决定。
上图还有个有意思的地方,数据流和控制流是分开的。Client 第三步将数据传给 Server A 后,从 A 向其它 Server 同步的过程就不在控制流内了。我理解就是数据到 A 后,A 就负责将数据传给 Primary,Primay 收完数据就负责把数据传给 Server B,不再有任何控制指令。Server B 第六步执行的前提是数据从 Primary 都能同步到 Server B。
分离控制流和数据流
我个人理解就是控制流不要带着数据到处跑。例如访问 Master 不用带着待存储的数据,客户端访问主副本,请求主副本写数据到磁盘也不用带着数据。
链式传输数据
即不是客户端直接将数据发至主副本和所有从副本的,而是由一个从副本开始,以 Chain 的方式逐步转发数据到 GFS 所有节点,而不是 Tree 的方式来传输。就是例如数据从 A 发到 B 再发到 C。而不是如从 A 并行的发去 B C。原因是如果客户端直接向 Chunk 所有所在节点传数据,客户端上传带宽会成为瓶颈,只能利用起三分之一的带宽。再有是传最近副本有利于高效利用网络。
此外,传输数据的时候 Chunkserver 是收到数据后就开始向下一个节点传数据。而不是等数据全收完了再转发。因为出入带宽是分开的,所以收数据的同时就转发数据不会对收数据有影响。
如下图所示是个网络拓扑图。平时服务我们关注的是从上到下,即南北方向的数据传输。但大数据这里更多会关注东西走向数据传输。南北走向的流量越大,对顶层核心交换机影响也越大。数据先传最近次副本,就是尽可能少占用南北带宽,多使用东西带宽。由次副本传数据到里更高一级交换机。
(2).jpg)
专用的复制数据操作
为了能完成文件数据复制,专门设计了专用的指令来做。避免数据反复传输。
GFS 就专门为文件复制设计了一个 Snapshot 指令,当客户端通过这个指令进行文件复制的时候,这个指令会通过控制流,下达到主副本服务器,主副本服务器再把这个指令下达到次副本服务器。不过接下来,客户端并不需要去读取或者写入数据,而是各个 chunkserver 会直接在本地把对应的 chunk 复制一份。
GFS 一致性
文件 Namespace 的修改都是原子的。因为所有 Namespace 的操作都由 Master 完成,并且 Master 有一套 Lock 机制来保障操作原子性。Master 会记录每个 Operation 到 Log,由这个 Log 来决定操作的全局顺序。
下面要说的一致性主要是文件内容数据操作的一致性。
一致性定义
- Consistent,一致的。这个就是指,多个客户端无论是从主副本读取数据,还是从次副本读取数据,读到的数据都是一样的。
- Defined,可能翻译为确定的。这个要求会高一些,首先必须满足一致性,其次是客户端写入到 GFS 的数据,能够完整地被读到。完整读到是说单次写入可能写不只一个 Chunk,写完后读这些 Chunk 的数据得到的结果和写入时一样。
在 GFS 的定义里,Defined 比 Consistent 要求更高,如果达到了 Defined 则就隐含的做到了 Consistent。
解释一下上面两个定义,Consistent 指的就是读数据从主副本和从副本读,数据是不是都相同。例如之前提到写数据如果在主副本写成功,从副本写失败。数据就是不一致的。
但就算数据是一致的,可能数据也是损坏的,不是我们想要的。因为写一个文件可能会有多个 Chunk,如果两个客户端并发的向同一个文件做覆盖写,可能导致处在非 Defined 状态。
前面说过,每个 GFS 文件由多个 Chunk 组成,每个 Chunk 可能落在不同的 Chunkserver 上。例如下图 Chunk 0 和 1 本来是同一个文件上连续的两个 Chunk,但被分配到了不同的 Chunkserver 上。加上需要备份三副本,所以看到一共有 6 个 Chunkserver 参与本次写入。客户端 A 要写 Hello World 到 Chunk 0 和 Chunk 1 上。客户端 B 要写 World Hello 也到 Chunk 0 和 1 上。
因为 GFS 不对 Client A 写操作先写哪个 Chunkserver 做要求,如果 A 在写 Server 1 2 3 的中途,B 也对 Chunk 0 做写入。最终 Server 1 2 3 上的结果可能有的是 Hello World,有的是 Hello Hello,有的是 World World。
.jpg)
出现上面问题的最主要原因是对 GFS 来说,随机的数据写入,没有原子性(Atomic)或者事务性(Transactional)。
总结一下 GFS 的操作的一致性保障如下:
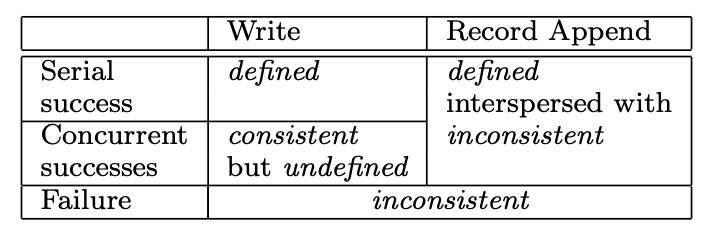
图上「Write」在这里指的是随机位置覆盖写。此外「Serial success」指的是没并发的情况下写入成功。「defined interspersed with inconsistent」是确定的,但文件可能夹杂不确定的数据。「Record Append」是以 Atomic 方式 At least once 的在 GFS 选择的 Offset 写入数据。
注意,Record Append 是个 GFS 提供的特殊操作,跟通常意义上的 Append 并不同。主要是客户端不会指定 Offset 且它具有 At least once 语义,即会重试。
表中「Serial success」是 Defined 是因为这里指的是没有并发操作,X Y 俩客户端一个写完了另一个再写,因为都是覆盖写,都成功的情况下是一致又是 Defined。如果是「Concurrent success」,可能会有上面说的 X Y 并发写电影的情况,写完后数据是一致的,但读出来文件是错的,即非 Defined 的。
第三种情况,追加写的情况下无论并发还是非并发,都能得到确定的数据,但可能因为数据重试而导致文件掺杂着不确定的数据。下面详述。
Record Append 追加写流程
- 检查当前的 chunk 是不是有足够空间,可以写得下现在要追加的记录。如果写得下,那么就把当前的追加记录写进去,同时,这个数据写入也会发送给其他次副本,在次副本上也写一遍。
- 如果当前 chunk 已经放不下了,那么它先会把当前 chunk 填满空数据,并且让次副本也一样填满空数据(其实我理解这里不会真的填满空数据,只是在哪里标记这个 Chunk 满了)。然后,主副本会告诉客户端,让它在下一个 chunk 上重新试验。这时候,客户端就会去一个新的 chunk 所在的 Chunk Server 进行记录追加。
- 因为主副本所在的 chunk server 控制了数据写入的操作顺序,并且数据只会往后追加,所以即使在有并发写入的情况下,请求也都会到主副本所在的同一个 chunkserver 上排队,也就不会有数据写入到同一块区域,覆盖掉已经被追加写入的数据的情况了。这里和前面并发覆盖写关键区别在于,待追加写入数据只向同一个 Chunk 写,这个 Chunk 有固定的 Chunk Server 负责,所以可以由这个 Chunk Server 决定并发写的次序。此外还一个关键点是下面要说的,追加写是有数据量上限要求的,所以单次追加写不可能写两个 Chunk。前面覆盖写因为没有 Padding 机制,不会检查当前 Chunk 还够不够写,所以就算限制单次覆盖写数据上限也不能保证单次覆盖写只写一个 Chunk。
- 而为了保障 chunk 里能存的下需要追加的数据,GFS 限制了一次记录追加的数据量是 16MB,而 chunkserver 里的一个 chunk 的大小是 64MB。所以,在记录追加需要在 chunk 里填空数据的时候,最多也就是填入 16MB,也就是 chunkserver 的存储空间最多会浪费 1/4。
从上面描述能看到,追加写的方式最多可能访问 Master 两次。第一次是先要找到 Last Chunk,如果 Last Chunk 能满足写要求,则追加写完就结束。如果不能满足,还得再去 Master 访问一下,获取下一个 Chunk 的 Chunkserver 地址,去新的 Chunkserver 完成追加写。
追加写可能 Undefined 原因
追加写可能夹杂非 Defined 数据原因主要是因为重试导致。如下图所示,有三个客户端 A、B、C 并发向同一个文件进行记录追加,写入数据 A、B、C。文件有三个副本。
首先 A Append 写入 A,但 A 在同步写入到 Replica 时候失败了,于是给 A 返回写入失败。数据处在不一致状态,前面图写过,写入失败 GFS 不保证一致性。数据在 Primary,Secondary 不一致。随后并发的追加写成功了 B C 客户端写的 B C 数据,B 和 C 因为写成功了,B C 数据处在一致又确定状态。
最后 Client A 知道 A 写入失败了,于是重试追加写 A,这次成功了。所以「追加写成功」可能是因为重试而成功的,这种时候可能存在不确定的数据在文件内。
简单说,GFS 在追加写场景承诺的一致性,叫做“At Least Once as an atomic unit”。就是单次写入是原子的,一致的。但整个文件并不一定。写入一份数据 A,在重试的情况下,至少会完整地在三个副本的同一个位置写入一次。但是也可能会因为失败,在某些副本里面写入多次。那么,在不断追加数据的情况下,你会看到大部分数据都是一致的,并且是确定的,但是整个文件中,会夹杂着少数不一致也不确定 undefined 的数据。
.jpg)
GFS 提供的一致性虽然弱但很多场景也足够用,应用层也能做一些事情来缓解或解决一致性问题。如果担心重试导致数据重复,可以对每次写入的数据加入唯一 ID 和时间戳(版本号),读数据时候根据唯一 ID 和版本号等信息做去重和排序。
如果担心写入数据失败导致数据不完整,可以自己再 对数据增加校验和 Checksum。
GFS 因为担心磁盘或硬件故障导致数据出错,自己就带着 Checksum 机制。每个 Chunk 会继续细分为 64KB 的 Block,对 Block 做 Checksum。Checksum 会存在内存和 Log 内。每次访问数据都会做校验,如果校验不通过 GFS 根本不会返回数据。即将 Corrupt 数据封闭在出错 Server 内部。
客户端或 Chunkserver 读取数据时候如果收到报错说数据 Corrupted,则会自动切换到另一个 Replica 来读数据。Master 也会感知到 Corrupted Chunk,从而从其它 Replica 读取正常的 Chunk 到出错的 Chunserver。等正常的 Chunk 拷贝完毕后,Master 会通知异常的 Chunkserver 清理出错的 Chunk。
Master 上其它操作
Namespace 操作和 Lock
Master 上 Namespace 操作是 Atomic 的。但有的操作,例如 Snapshot 可能开销很大,Master 又不能直接卡住完全不能工作,所以引入了 Lock 机制。将 Namespace 的一部分锁住,其它 Namespace 还能继续并发运行。
GFS 的 Namespace 虽然是 /foo/bar 这种格式的,但 Directory 并没有对应的 Description。Namespace 和 Metadata 对 GFS 来说实际只是个 Key Value 记录。Namespace 通过 Prefix Compression 来完成高效存储。
Namespace 上每个 Node 都有 Read Write Lock。操作 /d1/d2/d3 这种 Namespace 时候需要从 d1 开始一路将沿途的锁锁住。
拿 Snapshot 举例,要将 /home/user 拷贝到 /save/user,同时又有操作要创建个文件 /home/user/foo。于是 Snapshot 会占有 /home 和 /save 的读锁,以及 /home/user 和 /save/user 的写锁。创建文件操作会占用 /home, /home/user 的读锁,占 /home/user/foo 的写锁。因为 Snapshot 会占 /home/user 的写锁,所以 Snapshot 和 Creation 操作是互斥的,会正确按顺序执行。
这种加锁方式能有比较好的读并发能力,占住 Directory 的读锁后,就能避免这个 Directory 被增删改。文件名上加写锁用来避免同 Namespace 下相同文件名创建两次。
Creation,Re-replication,Rebalancing
创建 Chunk Replica 的时机如这个标题。
创建 Chunk 时候我们要找个地方存放 Chunk Replica,基于这些因素来评估:
- (1) We want to place new replicas on chunkservers with below-average disk space utilization. Over time this will equalize disk utilization across chunkservers. (2) We want to limit the number of “recent” creations on each chunkserver. Although creation itself is cheap, it reliably predicts immi- nent heavy write traffic because chunks are created when de- manded by writes, and in our append-once-read-many work- load they typically become practically read-only once they have been completely written. (3) As discussed above, we want to spread replicas of a chunk across racks.
Re-replication 是指当 Available Replica 数量少于 Replication Factor,需要再为 Chunk 补充 Replica 的情况。例如 Chunkserver 宕机了,Chunkserver 通过校验发现自己的某个 Chunk 的数据是错误的,Chunkserver 发现自己某个磁盘坏了,Replication Factor 提高了等。
Rebalancing 是 Master 定期根据磁盘空间和 Load 调配 Chunk Replica 的过程。
GC
GFS 文件删除是 Lazy 的。实际空间释放是后续才做。
删文件步骤如下:
- Master 给被删除的文件重命名,命一个特殊的名字,名字里有文件删除的时间。Master 会在 Operation Log 内将重命名操作写下来
- Master 定期扫所有文件,当文件被删除超过一定时间后,Master 完成文件的实际删除。即将 Namespace 和文件的关联解除。文件被实际删除前,被删除的文件还是能通过再次重命名而恢复。注意此时文件的 Chunk 还未从 Master 或 Chunkserver 删除
- Master 定期扫所有 Chunk,找到 Orphan Chunk 即没有 Namespace 指向的 Chunk,将这种 Chunk 的 Metadata 删除。此时被删除文件的 Chunk 从 Master 移除了
- Chunkserver 通过 Heartbeat 向 Master 上报自己的 Chunk 状态,Master 从中识别出已经没有对应 Metadata 的 Chunk,返回给 Chunkserver。Chunkserver 完成 Chunk 实际数据的删除
这种 Lazy 的删除方式好处是:
- 最大的好处是可靠。要靠 Master 主动去完成删除会有一大堆问题,请求发送失败等等,甚至 Master 根本不知道某个 Chunkserver 上有某个 Chunk。
- 能批量的来完成实际删除。批处理性能更好
- 提供了一点反悔的时间。万一删除的文件还想找回,还有办法
最大的问题是删除文件后,空间未释放。并且释放时机未知。但也有工程上的优化方案。
其它内容
Chunk Size
Chunk Size 选 64MB 也有点讲究,选的比较大,所以很容易引入 Internal Fragmentation。缓解办法是「Lazy space allocation」,但没看到解释是什么意思。可能是只在真的需要写的时候才分配 Chunk。
选这么大的 Chunk Size 好处是:
- 减少 Master 的访问。每次 Chunk 读写最多只有一次 Master 访问,Chunk 越大读写越容易落在同一个 Chunk 上。
- Chunk 大了客户端的操作也会落在同一个 Chunk 上,从而能复用与 Chunkserver 的 TCP 连接
- 减少在 Master 上维护的 Metadata 数据量
缺点是:
- Chunk 可能会有 Hotspot,因为可能本来是访问多个 Offset 但都落到了同一个 Chunk 上。但也有解决办法,例如让 Replication Factor 更大,让更多 Replica 来支持 Hotspot Chunk 的访问
Stale Replica Detection
每个 Chunk 都有个 Chunk version number。Master 每次给 Chunkserver 颁发 lease 时都会提升这个 Chunk Version。Master 和 Chunkserver 都会持久化存储这个 Version。
当 Chunkserver 启动,向 Master 报告自己拥有的 Chunk 时,Master 可以通过 Chunk Version 检查 Chunkserver 拥有的这个 Chunk 是不是 Stale 的。如果是,则 Master 会在正常 GC 过程中,将 Stale Chunk 删除。
参考资料
The Hadoop Distributed File Syste.pdf
https://www.infoq.cn/article/cap-twelve-years-later-how-the-rules-have-changed/